Ao final da unidade VI, esperamos que você seja capaz de:
- Identificar conceitos básicos de estatística;
- Analisar os diferentes tipos de variáveis qualitativas e quantitativas;
- Compreender a representação dos dados de um estudo por tabelas e gráficos;
- Identificar as medidas de tendência central e medidas de dispersão de um conjunto de dados;
- Entender os princípios probabilísticos baseados na distribuição normal e teste de hipóteses;
- Compreender a classificação dos estudos epidemiológicos.
Meta da Unidade
Neste capítulo vamos conhecer os princípios gerais da bioestatística, objetivando capacitar você a realizar uma leitura crítica da literatura científica, elaborar projetos de pesquisa bem estruturados e análises de dados
PRINCÍPIOS DE BIOESTATÍSTICA
INTRODUÇÃO
A estatística é uma ciência que se dedica à coleta, análise e interpretação de dados quantitativos de tal forma que seja possível efetuar julgamentos racionais sobre eles. Incorporada ao campo biológico e médico, a bioestatística é considerada um ramo mais amplo da área da estatística que avalia com seguridade dados médicos e biológicos, com uso de ferramentas avançadas e softwares estatísticos, permitindo obter conclusões sobre o fato ou problema estudado. A estatística pode ser classificada em estatística descritiva ou inferencial.
A estatística descritiva geralmente é utilizada nas etapas iniciais dos trabalhos e se refere à maneira de representar dados em tabelas e gráficos, resumi-los por meio de algumas medidas sem, contudo, tirar quaisquer informações sobre um grupo maior. Já a estatística inferencial é usada para comparar diferentes amostras ou estabelecer associações que gerem conclusões as quais possam ser extrapoladas para o conjunto de uma população.
É muito importante que profissionais da saúde tenham uma sólida formação nos conceitos básicos de bioestatística, pois esse conhecimento é essencial para a leitura crítica de artigos científicos, os quais são imprescindíveis, por sua vez, para que o profissional se mantenha atualizado ao longo de sua carreira.
Através da bioestatística, o cirurgião-dentista consegue avaliar a confiabilidade dos resultados de um estudo clínico, tendo a consciência de que nem toda informação publicada é de qualidade. Além disso, como visto no capítulo 2, a estatística é importante para a avaliação dos dados epidemiológicos, os quais são cruciais para o desenvolvimento de programas de saúde de uma população. A bioestatística também é importante para o desenvolvimento de projetos de pesquisa, algo cada vez mais exigido no currículo de graduandos da área da saúde.
CONCEITOS BÁSICOS EM BIOESTATÍSTICA
Como toda ciência, a estatística apresenta um conjunto de termos e conceitos próprios, os quais muitas vezes possuem significado diferente daquele utilizado na linguagem coloquial. Portanto, alguns conceitos básicos devem ser compreendidos de antemão:
POPULAÇÃO
Em estatística, população significa o conjunto de elementos com, no mínimo, uma característica em comum, sendo essa característica determinada de acordo com o interesse do estudo. Em estudos clínicos, uma população é comumente definida por características demográficas e clínicas. Por exemplo, crianças com cárie, pacientes com câncer, adolescentes com gengivite etc.
AMOSTRA
É um subconjunto da população. A amostra estudada deve fornecer informações sobre a população que a originou, sendo representativa dessa população. Em outras palavras, a amostra estudada deve possibilitar gerar dados que possam ser inferidos para a população da qual faz parte. Em estudos clínicos, a amostra é normalmente definida por características geográficas e temporais (por exemplo, número de crianças com cárie em Belo Horizonte, no ano de 2020).
Para que a amostra caracterize a população em estudo, ela deve apresentar um número suficiente de unidades amostrais e ser selecionada a partir de processos que assegurem a sua representatividade em relação à população da qual ela foi extraída. E por que não estudar a população toda? Em estudos científicos, o custo para obtenção de informações de uma população toda é muito alto, isso sem mencionar que o tempo para a obtenção de todos esses dados seria muito longo. Além disso, para alguns tipos de estudo, é impossível, por questões de logística, obter todos os dados. Por exemplo, estudo da poluição atmosférica de uma cidade.
DADOS
São as informações obtidas em cada unidade amostral sobre a variável estudada. Por exemplo, o dado de um estudo poderá ser o número do ceo-d de cada criança.
VARIÁVEL
Uma variável é uma característica, propriedade ou atributo de uma unidade da população, cujo valor pode variar entre as unidades da população. A variável do exemplo anterior é cárie. Uma das formas de estudar cárie em crianças é contar o número de dentes decíduos cariados.
As variáveis podem ser classificadas da seguinte forma (FIG. 1):
Figura 1 - Classificação das variáveis e suas escolas de medida
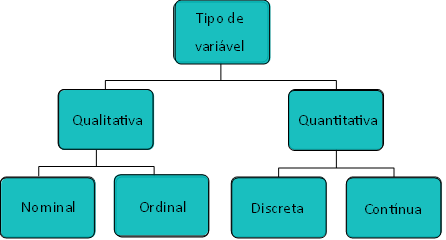
Uma variável qualitativa é aquela que analisa alguma característica da unidade amostral de forma não quantificável. Essa pode ser exemplificada pelo sexo (masculino ou feminino), nível de escolaridade (nível fundamental, médio ou superior), satisfação (baixa, média, alta) e assim por diante. As variáveis qualitativas podem ser representadas por duas formas de medida: escala nominal ou ordinal. Nas escalas nominais, os dados são distribuídos em categorias, as quais podem ser dicotômicas como sim ou não, masculino ou feminino, etc. Uma variável qualitativa também pode assumir uma escala ordinal (ex.: classificação dos estágios dos tumores, 0 a IV).
Uma variável quantitativa é aquela que estuda alguma característica mensurável, quantificável. As variáveis quantitativas assumem dois tipos de escala: contínua, quando os dados podem assumir quaisquer valores numéricos, tanto inteiros quando fracionários (ex.: peso, comprimento, resistência) ou discretas, quando os dados assumem apenas um número finito ou infinito contável de valores e, assim, somente fazem sentido serem representados por valores inteiros (ex.: número de filhos, número de bactérias por litro de leite, número de cigarros fumados por dia).
PARA SABER
Uma variável originalmente quantitativa pode ser coletada de forma qualitativa. Por exemplo, a variável idade, medida em anos completos, é quantitativa (contínua); mas, se for informada apenas a faixa etária (0 a 5 anos, 6 a 10 anos, etc…), é qualitativa (ordinal).
TABELAS
A tabela é composta pelos seguintes elementos:
- Essenciais: título, cabeçalho e corpo (colunas e linhas);
- Complementares: Fonte e notas (rodapé).
Componentes essenciais de uma tabela:
Título: colocado sempre na parte superior, deve ser claro e conciso, indicando o que foi estudado, como foi estudado, onde foi estudado e o período do estudo.
Cabeçalho: linha superior que designa o conteúdo de cada coluna
Coluna indicadora: designa o conteúdo de cada linha da tabela.
Corpo: conjunto de linhas e colunas que contém os dados coletados.
Componentes essenciais de uma tabela:
Fonte: indica a fonte responsável pelos dados da tabela. Colocada por honestidade científica e para permitir consulta ao original.
Notas: fornecem esclarecimentos de ordem geral.
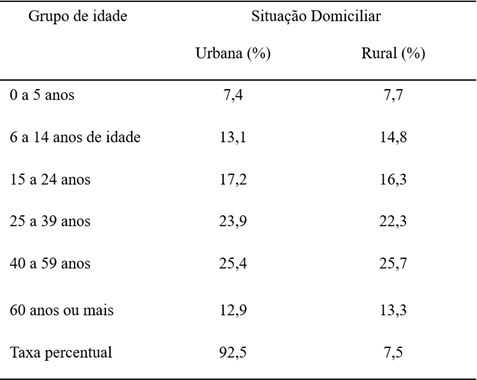
Exemplo:
Tabela 1 - Situação domiciliar na cidade de Muriaé por grupo de idade em 2010
GRÁFICOS
Os gráficos podem ser considerados uma representação dinâmica dos dados das tabelas, sendo mais eficientes na sinalização de tendências. Quando optamos por usar um gráfico, não devemos utilizar uma tabela para representar o mesmo conjunto de dados, isto é, devemos optar por uma forma ou outra de representação dos dados.
Sabe-se que a escolha do tipo de gráfico (barras, lineares, de setores, entre outros) está relacionada ao tipo de informação a ser ilustrada. Sugere-se o uso de:
- Gráficos de linhas (FIG. 2), para dados crescentes e decrescentes, pois as linhas unindo os pontos enfatizam o movimento;
- Gráficos de setores (FIG. 3), para dados proporcionais;
- Gráficos de barras (FIG. 4), para estudos temporais, dados comparativos de diferentes variáveis.
Figura 2 - CPO-D médio no Brasil
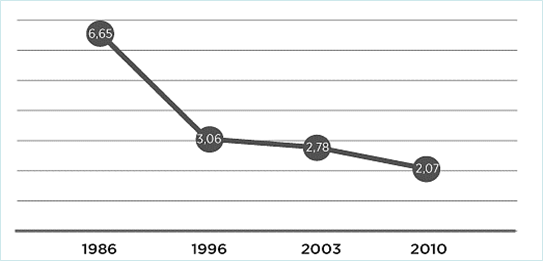
Figura 3 - Percentual de indivíduos com maloclusão no Brasil no ano de 2010
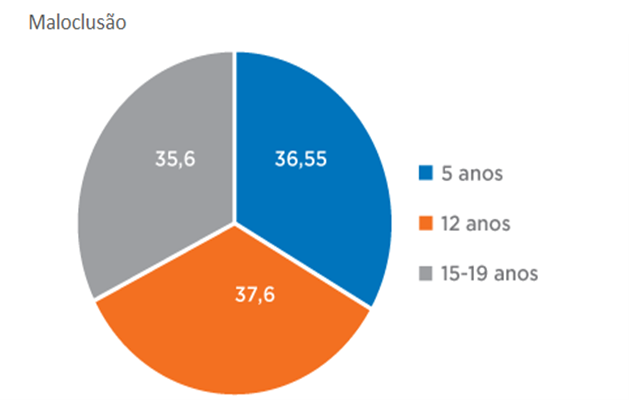
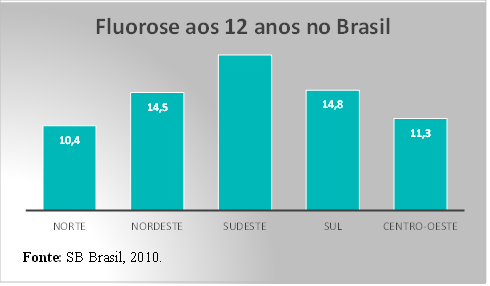
Figura 4 - Distribuição percentual de crianças de 12 anos com fluorose no Brasil por regiões
MEDIDAS DE TENDÊNCIA CENTRAL
Os dados provenientes de variáveis numéricas são normalmente expressos por valores numéricos que representam os dados de forma resumida e que dão uma noção da distribuição dos valores dentro do conjunto de dados. Esses valores são denominados de medidas de tendência central e medidas de dispersão.
MÉDIA (X)
A média é a medida de tendência central mais largamente empregada em estatística. Entretanto, o valor da média é afetado pela presença de valores discrepantes dentro do conjunto de dados. Portanto, a presença de um valor único muito baixo ou muito alto pode influenciar o valor dessa medida, elevando-o ou abaixando-o, o que pode torná-la menos representativa do conjunto de dados. A média é o resultado da soma dos valores de todas as observações, dividida pelo número de observações.
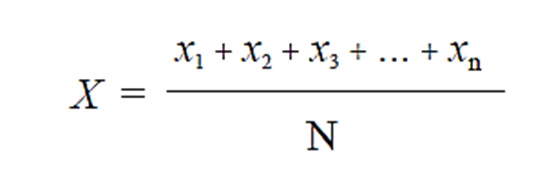
MEDIANA (Me)
A mediana corresponde ao valor que se localiza no centro da distribuição dos dados após sua ordenação, sendo obtida obtido após todas as observações serem colocadas em ordem crescente (ou decrescente), de acordo com o seu valor. Ao contrário da média, a mediana não é afetada por valores extremos, daí ser preferida em séries com distribuição assimétrica. Além disso, pode ser empregada para dados qualitativos ordinais, uma vez que o seu cálculo não leva em consideração o valor real dos dados.
Exemplo: Dada a variável X = {3, 0, 8, 5, 9}, a mediana será 5.
Para encontrar a mediana:
Coloque os dados em ordem crescente. No exemplo acima, teríamos então: X = {0, 3, 5, 8, 9}.
Se o número de dados for ímpar, a mediana será o dado no centro da lista. Se o número de dados for par, a mediana será a média dos dois dados do centro da lista.
MODA (Mo)
A moda indica o valor que aparece com maior frequência na amostra., ou seja, aquele que se repete o maior número de vezes. A moda é útil quando há muitos valores repetidos em um conjunto de dados. Pode ser empregada para qualquer tipo de variável e qualquer tipo de escala, ao contrário do que ocorre com a média e a mediana.
Exemplo: a moda de {4, 2, 4, 3, 2, 2} é 2 porque ele aparece três vezes, ou seja, aparece mais que qualquer outro número.
Veja a seguir, na Tabela 2, algumas informações importantes sobre as medidas de tendência central.
| VANTAGENS | LIMITAÇÕES | |||
|---|---|---|---|---|
|
Média |
Utiliza todos os valores da amostra. Fácil de incluir em funções matemáticas |
É influência por valores extremos. |
||
|
Mediana |
Menos sensível a valores extremos que a média. Pode ser determinada mesmo quando não se conhece todos os valores de um conjunto de dados. |
Mais difícil de ser determinada para grande quantidade de dados. Não utiliza todos os dados da amostra. |
||
|
Moda |
Representa um valor típico |
Não tem função em certos conjuntos de dados. |
||
MEDIDAS DE DISPERSÃO
As medidas de tendência central são, na maioria dos casos, insuficientes para descrever um conjunto de dados, pois elas não mostram como os dados variam ou se distribuem em torno do seu ponto médio. Essa informação pode ser obtida pelas medidas de dispersão, que são: amplitude, o desvio-padrão, a variância, o coeficiente de variação e o desvio-interquartílico.
AMPLITUDE (A)
A amplitude representa a diferença entre o maior e o menor valor de um conjunto de dados. Embora seja de fácil cálculo e interpretação, sua aplicação é limitada pelo fato de não fornecer uma noção dos valores numéricos do conjunto de dados nem de como se distribuem entre esses valores extremos.
DESVIO-PADRÃO (s)
O desvio-padrão é a medida de dispersão mais largamente empregada na descrição de dados. Embora o cálculo do desvio-padrão seja, de certa forma, complexo, ele se baseia na determinação do desvio ou diferença de cada dado (X) em relação à média do conjunto. Ao se determinar o quanto cada dado se afasta da média, eleva-se cada um desses desvios ao quadrado. Assim, o desvio padrão é a raiz quadrada da variância, são denotados s (para amostra) e σ (para população).
Em palavras simples, o desvio- padrão representa o padrão de oscilações que os valores da série apresentam em relação à média. É frequentemente usado em conjunto com a média e, como essa, exige-se que as variáveis sejam do tipo numérica e é afetado por valores extremos. Para o cálculo do desvio-padrão, utiliza-se a seguinte fórmula:
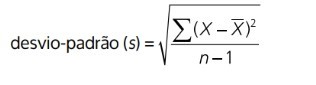
VARIÂNCIA (S²)
Matematicamente, é o valor do
desvio-padrão elevado ao quadrado, importante para análises estatísticas
avançadas.
COEFICIENTE DE VARIAÇÃO (CV)
É a dispersão relativa dos dados, representada pela razão entre o desvio–padrão e a média, multiplicada por 100, sendo representado pela seguinte fórmula:
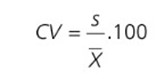
DESVIO-INTERQUARTÍLICO
É uma medida de dispersão baseada em percentis. Os percentis são percentagem das observações abaixo do ponto indicado quando todas as observações são ordenadas de maneira decrescente. A mediana corresponde ao percentil 50. Geralmente são apresentados os quartis, isto é, os percentis 25, 50 e 75. A amplitude interquartílica é o intervalo existente entre o percentil 25 e o percentil 75.
ESTATÍSTICA INFERENCIAL
O objetivo da aplicação da bioestatística em estudos científicos não se restringe apenas à descrição dos valores e da distribuição dos dados de uma amostra. Na maioria dos casos, o pesquisador busca fazer deduções sobre as características de uma população a partir da informação contida na amostra, o que se conhece como inferência estatística.
A estatística inferencial é extremamente útil na análise de populações e tendências e sua função é interpretar, fazer projeções e comparações. A seguir, são apresentados conceitos básicos para entendimento de princípios probabilísticos baseados na distribuição normal (ou curva normal) e teste de hipóteses.
DISTRIBUIÇÃO NORMAL
Uma distribuição estatística é uma função que define uma curva, e a área sob essa curva determina a probabilidade de ocorrer o evento por ela correlacionado. A distribuição normal, também chamada Gaussiana, é a mais familiar das distribuições de probabilidade e uma das mais importantes em estatística. Em meados do século XIX, Friedrich Gauss, com seus estudos sobre eventos da natureza, observou um comportamento padrão entre as amostras estudadas por ele, mostrando que parte dos eventos ficam em torno de um valor médio, com uma certa variabilidade.
A distribuição normal pode representar diferentes processos práticos, como altura ou peso de um grupo de indivíduos, a pressão sanguínea de uma população, o tempo que um grupo de alunos usa na realização de provas. Ela é caracterizada por uma função de probabilidade, cujo gráfico descreve uma curva em forma de sino, como mostra a FIG. 5. A partir dos parâmetros de média (μ) e desvio-padrão (σ) é possível determinar o valor da curva normal.
Figura 5 - Curva normal
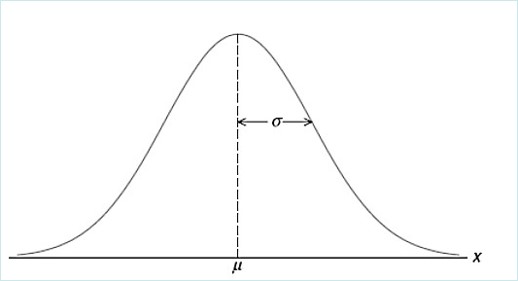
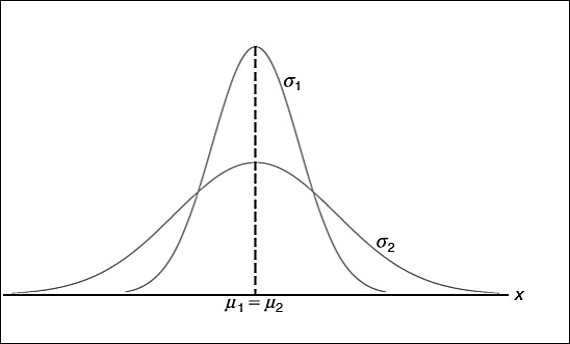
É importante salientar que não há apenas uma curva normal. Para cada valor diferente da média e do desvio padrão, há uma curva normal diferente. Sabe-se que a alteração da média muda a posição da distribuição dos dados, e a alteração do desvio-padrão modifica o padrão da dispersão dos dados (Figura 3 e 4).
Figura 6 - Duas amostras com médias diferentes e com desvios-padrão semelhantes
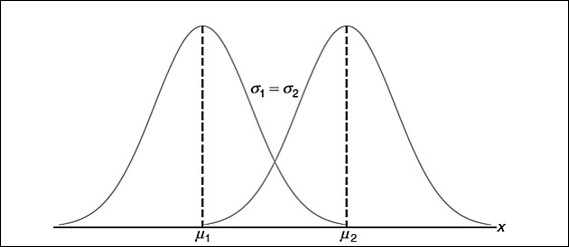
Figura 7 - Duas amostras com médias iguais, porém com desvios-padrão diferentes
PROPRIEDADES DA DISTRIBUIÇÃO NORMAL:
- A representação gráfica dos dados mostra uma curva em forma de sino;
- A média, a moda e a mediana possuem valores semelhantes;
- A curva é simétrica em relação a uma reta vertical que passa pela média;
- Em cada lado da curva existe um ponto de inflexão, que corresponde ao valor de 1 (um) desvio-padrão;
- A área entre a curva e o eixo horizontal (eixo x) totaliza 100%;
- Aproximadamente 67% dos dados se localizam entre a média e ± 1s;
- Aproximadamente 95% dos dados se localizam entre a média e ± 2s;
- Aproximadamente 99,7% dos dados se localizam entre a média e ± 3s.
TESTE DE HIPÓTESES
O teste de hipóteses fornece ferramentas que nos permitem rejeitar ou não uma hipótese estatística através da evidência fornecida pela amostra. O objetivo de se testar uma hipótese é obter, a partir de dados de uma amostra limitada, conclusões que possam ser generalizadas para a população da qual foi originada a amostra.
Vamos imaginar que duas amostras tenham sido obtidas a partir de uma população e o pesquisador decida testar se, em relação a uma determinada variável, as amostras são iguais ou diferentes. Ou seja, o pesquisador deseja descobrir se a diferença encontrada entre as duas amostras é devida ao acaso, ou se, de fato, as amostras são diferentes em relação àquela variável.
Inicialmente, são definidas duas hipóteses: a hipótese nula (H0), que é assumida como verdadeira até que se prove o contrário, e a hipótese alternativa (H1), afirmando que há diferença entre elas. Após a aplicação de um teste estatístico apropriado para a comparação das médias, se existir evidência amostral para se rejeitar a hipótese nula, então conclui-se pela hipótese alternativa. Do contrário, se não for comprovada diferença entre os grupos, a hipótese nula não é rejeitada. A escolha do teste estatístico apropriado é um importante tema que não será discutido nesta unidade devido à sua alta complexidade.
PARA SABER
Ressalta-se que o fato de a hipótese nula não ser rejeitada não implica, necessariamente, que ela seja verdadeira, mas que as evidências obtidas não são suficientes para rejeitá-la.
Ao realizar um teste estatístico, um conceito importante é o nível de significância, representado pela letra grega alfa (α), que corresponde ao “risco assumido” pelo pesquisador ao fazer uma inferência estatística. O nível de significância é a probabilidade de se rejeitar a hipótese nula quando ela é verdadeira. Por exemplo, um nível de significância de 0,05 indica um risco de 5% de concluir que existe uma diferença quando não há diferença real. Como é extremamente indesejável se rejeitar uma hipótese nula verdadeira, esse “risco assumido” deve ser bastante baixo. Os valores comumente utilizados são de 0,05 (5%), 0,01 (1%) e 0,001 (0,1%). O nível de significância está intimamente relacionado ao valor de p (valor de probabilidade), calculado após a aplicação do teste estatístico.
O valor p é considerado a probabilidade de o resultado observado ser devido apenas ao acaso. Se o valor p for menor que o valor de α, a hipótese nula é rejeitada. Ou seja, a hipótese nula (ou de igualdade entre as amostras) será rejeitada se os valores p corresponderem a p < 0,05 (para α= 5%), p < 0,01 (para α= 1%) ou p < 0,001 (para α= 0,1). Considera-se, nesse caso, que há diferença estatisticamente significativa entre as amostras. Caso ocorra o contrário, ou seja, caso o valor p seja maior que o valor de α, a hipótese nula não é rejeitada, e a diferença entre as amostras é, então, considerada não significativa.
Portanto:
valor p < 0, 05 ⇒ Resultado estatisticamente significativo. Hipótese H0 rejeitada.
valor p > 0, 05 ⇒ Resultado estatisticamente não-significativo. Aceitar H0 como verdadeira
Um resultado estatisticamente significativo deve ser interpretado como a rejeição da hipótese nula.
Dois erros são possíveis ao testar uma hipótese: rejeitar a hipótese nula quando ela for verdadeira (erro tipo I) ou não a rejeitar quando ela for falsa (erro tipo II).
Erro tipo I:
- Decisão de rejeitar a H0 quando de fato a H0 é verdadeira;
- O emprego de um valor de α pequeno (p < 0,05) é necessária para se evitar o erro tipo I;
- Amostras pequenas e análises sucessivas podem aumentar o risco de se ocorrência em erro do tipo I.
Erro tipo II:
- Decisão de não rejeitar a H0 quando de fato a H0 é falsa;
- Resultante da grande variabilidade dos dados, normalmente devido à presença amostras pequenas ou métodos experimentais incorretos.
CLASSIFICAÇÃO DOS ESTUDOS EPIDEMIOLÓGICOS
A bioestatística é uma ferramenta importante para a avaliação de estudos epidemiológicos, fornecendo, assim, dados relevantes para a tomada de decisão na prática médica e odontológica. Dessa forma, a solidez de uma evidência é dependente tanto do rigor metodológico quanto do tipo de estudo planejado. Os estudos epidemiológicos podem ser classificados em observacionais ou experimentais.
Observacionais: o pesquisador coleta a informação sobre os atributos ou faz as medições necessárias, mas não interfere nas unidades amostrais. Por exemplo, quando se pretende determinar o estado nutricional de uma certa população. De uma maneira geral, os estudos epidemiológicos observacionais podem ser classificados em descritivos e analíticos. Um estudo descritivo limita-se a descrever a ocorrência de uma doença em uma população, sendo, frequentemente, o primeiro passo de uma investigação epidemiológica. Os principais estudos descritivos incluem série de casos (descrição de uma série de pacientes) ou relatos de caso (descrições de pacientes individuais). Os delineamentos observacionais analíticos procuram quantificar a relação entre dois fatores, ou seja, o efeito de uma exposição sobre um desfecho. Estes incluem estudos observacionais do tipo caso-controle, de coorte e estduos populacionais tranversais.
Experimentais: o pesquisador deliberadamente influencia os indivíduos e pesquisa o efeito da intervenção. Por exemplo, estudos em que se pretende conhecer o efeito de uma nova dieta sobre a rapidez em aumentar os níveis de cálcio. Os estudos experimentais podem ser classificados de acordo com a forma de alocação dos indivíduos nos grupos a serem estudados, resultando em dois tipos: os estudos experimentais randomizados (quando a manipulação artificial do fator de estudo é feita com randomização) e estudos experimentais não randomizados ou estudos quase- experimentais (quando a manipulação artificial do fator de estudo é feita sem randomização).
Os níveis de evidência desses estudos estão hierarquizados de acordo com os seus graus de confiança que estão relacionados à sua qualidade metodológica. No topo da pirâmide, encontram-se as revisões sistemáticas e metanálises, seguidas de ensaios clínicos controlados randomizados, estudos de coorte, estudos de caso-controle, série de casos, relato de casos e, por fim, a opinião de especialistas/estudos in vitro ou com animais.
A seguir, vamos entender com maior profundidade algumas características dos delineamentos observacionais analíticos.
ESTUDOS DE CASO-CONTROLE
Estudos de caso-controle constituem uma forma relativamente simples de investigar a causa das doenças, particularmente doenças raras. Nesse tipo de estudo, um grupo de pacientes que apresenta uma determinada doença de interesse (caso) e um grupo de indivíduos sem a doença (controle) são selecionados para a investigação. Os dois grupos são comparados para se descobrir quais fatores estão associados com a doença em estudo.
A comparação é feita com base na proporção de indivíduos que apresentaram a exposição ou característica de interesse. Se houver associação entre a exposição e a doença, a proporção de pessoas expostas entre os casos será maior do que entre os controles. Dessa forma, os pesquisadores “olham para o passado” para medir a frequência de exposição a um possível fator de risco nos dois grupos. Por essa razão, os estudos de caso-controle são também chamados de estudos retrospectivos.
A medida utilizada para detectar a magnitude dessa associação é a razão de chances ou odds ratio.
ESTUDOS TRANSVERSAIS
Estudos transversais são aqueles em que grupos de indivíduos são observados uma única vez, coma intenção de analisar a situação naquele instante em que são feitas as observações. Esse tipo de estudo apresenta como finalidade a mensuração da prevalência de uma doença (proporção da população que tem a doença num determinado momento) e, por essa razão, são frequentemente chamados de estudos de prevalência. Também podem ser denominados de estudos seccionais ou inquéritos. Devem ser realizados em amostras representativas e aleatórias da população, independentemente da existência da exposição e do desfecho. A medida de associação utilizada nesse caso é chamada de razão de prevalências (RP), que é calculada pelas diferentes prevalências entre expostos e não expostos a esses fatores.
ESTUDOS DE COORTE
Estudo de coorte também pode ser chamado de longitudinal, pois os dados são coletados em diferentes pontos no tempo. Ao contrário do estudo de caso-controle, um estudo de coorte normalmente tem início com indivíduos sadios, os quais são classificados em um ou mais grupos com base na presença, ausência ou diferentes graus de exposição a um determinado fator, sendo, então, acompanhados por um período específico de tempo para verificar a incidência da doença/condição relacionada à saúde em cada grupo.
Os estudos de coorte permitem determinar a incidência da doença entre expostos e não expostos e conhecer a sua história natural. A principal limitação para o desenvolvimento de um estudo de coorte, além do seu custo financeiro, é a perda de participantes ao longo do seguimento por conta de recusas para continuar participando do estudo, mudanças de endereços ou emigração. O estudo de coorte também pode ser conduzido a partir da identificação de registros passados e acompanhados daquele momento em diante até o presente (também chamado de coorte retrospectiva).
RESUMO DA UNIDADE
Este capítulo permite a compreensão de conceitos básicos de estatística, assim como a importância da sua aplicação na área das ciências biológicas.
A estatística descritiva é um ramo da estatística que aplica várias técnicas para descrever e resumir um conjunto de dados com a utilização de gráficos e tabelas.
As medidas de tendência central indicam um valor que melhor representa todo o conjunto de dados, ou seja, mostram a tendência da concentração dos valores observados. As principais medidas de posição são: a média, a mediana e a moda.
As medidas de dispersão são utilizadas para indicar o grau de variação dos elementos de um conjunto numérico em relação à sua média. As principais medidas de dispersão são: amplitude, desvio-padrão, variância e coeficiente de variação.
A estatística inferencial é o estudo de técnicas que possibilitem a extrapolação das informações e conclusões obtidas a partir de subconjuntos de dados, ou seja, procura estabelecer conclusões para toda uma população, quando apenas se observou uma parte dela.
A distribuição normal é um modelo matemático no qual pode-se estudar a distribuição das frequências tendo como base a média e o desvio-padrão.
Em experimentos comparativos, nos quais uma nova técnica é comparada com o padrão, para determinar se sua superioridade pode ser corroborada pela evidência experimental, é necessário formular a hipótese nula e a hipótese alternativa.
O erro tipo I é o erro resultante quando uma hipótese nula verdadeira é rejeitada, ou seja, é verificada uma diferença quando esta não existe. O erro tipo II é o erro resultante quando uma hipótese nula falsa não é rejeitada, ou seja, uma diferença não é detectada quando ela de fato existe.
O valor-p é, basicamente, um parâmetro estatístico que indica se determinada hipótese, formulada a priori, deve ser rejeitada ou não.
Os estudos epidemiológicos podem ser classificados em observacionais ou experimentais.
Assista aos vídeos desta Unidade e aprofunde mais sobre o assunto:
REFERÊNCIAS
- BUSSAB, W.O.; MORETTIN, P.A. Estatística básica. São Paulo: Saraiva, 2003.
- CALLEGARI-JACQUES, Sidia M. Bioestatística: princípios e aplicações. Grupo
- A, 2003. E-book. ISBN 9788536311449. Disponível em: https://integrada.minhabiblioteca.com.br
/#/books/9788536311449/. Acesso em: 17 abr. 2023. - Dental Press Journal of Orthodontics, v. 15, p. 101-106, 2010.
- ESTRELA, Carlos. Metodologia científica: ciência, ensino, pesquisa. Artes Médicas, 2018.
- PAGANO, Marcello; GAUVREAU, Kimberlee. Princípios de bioestatística. In: Princípios de bioestatística. 2011.
- NORMANDO, David; TJÄDERHANE, Leo; QUINTÃO, Cátia Cardoso Abdo. A PowerPoint®-based guide to assist in choosing the suitable statistical test.